The coronavirus pandemic has certainly shown just how much the world depends not just on accurate and readily available datasets but also the ability of scientists and data analysts to make sense of that data. All of us are at the mercy of those experts to interpret this data correctly – our lives could quite literally depend on it.
Thankfully we live in a world where the tools are available to allow anyone, with a bit of effort, to learn how to analyse data themselves and not just rely on the experts to tell us what is happening.
The programming language Python, coupled with the pandas dataset analysis library and Bokeh interactive visualisation library, provide a robust and professional set of tools to begin analysing data of all sorts and get it into the right format.
Data on the coronavirus pandemic is available from lots of sources including the UK’s Office for National Statistics as well as the World Health Organisation. I’ve been using data from DataHub which provides datasets in different formats (CSV, Excel, JSON) across a range of topics including climate change, healthcare, economics and demographics. You can find their coronavirus related datasets here.
I’ve created a set of resources which I’ve been using to learn Python and some of its related libraries which is available on my GitHub page here. You’ll also find the project which I’ve been using to analyse some of the COVID-19 data around the world here.
The snippet of code below shows how to load a CSV file into a panda DataFrame – a 2-dimensional data structure that can store data of different types in columns that is similar to a spreadsheet or SQL table.
# Return COVID-19 info for country, province and date.
def covid_info_data(country, province, date):
df4 = pd.DataFrame()
if (country != "") and (date != ""):
try:
# Read dataset as a panda dataframe
df1 = pd.read_csv(path + coviddata)
# Check if country has an alternate name for this dataset
if country in alternatives:
country = alternatives[country]
# Get subset of data for specified country/region
df2 = df1[df1["Country/Region"] == country]
# Get subset of data for specified date
df3 = df2[df2["Date"] == date]
# Get subset of data for specified province. If none specified but there
# are provinces the current dataframe will contain all with the first one being
# country and province as 'NaN'. In that case just select country otherwise select
# province as well.
if province == "":
df4 = df3[df3["Province/State"].isnull()]
else:
df4 = df3[df3["Province/State"] == province]
except FileNotFoundError:
print("Invalid file or path")
# Return selected covid data from last subset
return df4
The first ten rows from the DataFrame df1 shows the data from the first country (Afghanistan).
Date Country/Region Province/State Lat Long Confirmed Recovered Deaths
0 2020-01-22 Afghanistan NaN 33.0 65.0 0.0 0.0 0.0
1 2020-01-23 Afghanistan NaN 33.0 65.0 0.0 0.0 0.0
2 2020-01-24 Afghanistan NaN 33.0 65.0 0.0 0.0 0.0
3 2020-01-25 Afghanistan NaN 33.0 65.0 0.0 0.0 0.0
4 2020-01-26 Afghanistan NaN 33.0 65.0 0.0 0.0 0.0
Three further subsets of data are made, the final one is for a specific country showing the COVID-19 data for a particular date (the UK on 7th May in this case).
Date Country/Region Province/State Lat Long Confirmed Recovered Deaths
26428 2020-05-07 United Kingdom NaN 55.3781 -3.436 206715.0 0.0 30615.0
Once the dataset has been obtained the information can be printed in a more readable way. Here’s a summary of information for the UK on 9th May.
Date: 2020-05-09
Country: United Kingdom
Province: No province
Confirmed: 215,260
Recovered: 0
Deaths: 31,587
Population: 66,460,344
Confirmed/100,000: 323.89
Deaths/100,000: 47.53
Percent Deaths/Confirmed: 14.67
Obviously there are lots of ways of analysing this dataset as well as how to display it. Graphs are always a good way of showing information and Bokeh is a nice and relatively simple to use Python library for creating a range of different graphs. Here’s how Bokeh can be used to create a simple line graph of COVID-19 deaths over a period of time.
from datetime import datetime as dt
from bokeh.plotting import figure, output_file, show
from bokeh.models import DatetimeTickFormatter
def graph_covid_rate(df):
x = []
y = []
country = df.values[0][1]
for deaths, date in zip(df['Deaths'], df['Date']):
y.append(deaths)
date_obj = dt.strptime(date, "%Y-%m-%d")
x.append(date_obj)
# output to static HTML file
output_file("lines.html")
# create a new plot with a title and axis labels
p = figure(title="COVID-19 Deaths for "+country, x_axis_label='Date', y_axis_label='Deaths', x_axis_type='datetime')
# add a line renderer with legend and line thickness
p.line(x, y, legend_label="COVID-19 Deaths for "+country, line_width=3, line_color="green")
p.xaxis.major_label_orientation = 3/4
# show the results
show(p)
Bokeh creates an HTML file of an interactive graph. Here’s the one the above code creates, again for the UK, for the period 2020-02-01 to 2020-05-09.
As a recently retired software architect (who has now started a new career working for Digital Innovators, a company addressing the digital skills gap) coding is still important to me. I’m a believer in the Architect’s Don’t Code anti-pattern believing that design and coding are two sides of the same coin and you cannot design if you cannot code (and you cannot code if you cannot design). These days there really is no excuse not to keep your coding skills up to date with the vast array of resources available to everyone with just a few clicks and Google searches.
I also see coding as not just a way of keeping my own skills up to date and to teach others vital digital skills, but also, as this article helpfully points out, as a way of helping solve problems of all kinds. Coding is a skill for life that is vitally important for young people entering the workplace to at least have a rudimentary understanding of to help them not just get a job but to also understand more of the world in these incredibly uncertain times.
An article on the front page of the Observer, Revealed: how drugs giants can access your health records, caught my eye this week. In summary the article highlights that the Department of Health and Social Care (DHSC) has been selling the medical data of NHS patients to international drugs companies and have “misled” the public that the information contained in the records would be “anonymous”.
The data in question is collated from GP surgeries and hospitals and, according to “senior NHS figures”, can “routinely be linked back to individual patients’ medical records via their GP surgeries.” Apparently there is “clear evidence” that companies have identified individuals whose medical histories are of “particular interest.” The DHSC have replied by saying it only sells information after “thorough measures” have been taken to ensure patient anonymity.
As with many articles like this it is frustrating when some of the more technical aspects are not fully explained. Whilst I understand the importance of keeping their general readership on board and not frightening them too much with the intricacies of statistics or cryptography it would be nice to know a bit more about how these records are being made anonymous.
There is a hint of this in the Observer report when it states that the CPRD (the Clinical Practice Research Datalink ) says the data made available for research was “anonymous” but, following the Observer’s story, it changed the wording to say that the data from GPs and hospitals had been “anonymised”. This is a crucial difference. One of the more common methods of ‘anonymisation’ is to obscure or redact some bits of information. So, for example, a record could have patient names removed and ages and postcodes “coarsened”, that is only the first part of a postcode (e.g. SW1A rather than SW1A 2AA) are included and ages are placed in a range rather than using someones actual age (e.g. 60-70 rather than 63).
The problem with anonymising data records is that they are prone to what is referred to as data re-identification or de-anonymisation. This is the practice of matching anonymous data with publicly available information in order to discover the individual to which the data belongs. One of the more famous examples of this is the competition that Netflix organised encouraging people to improve its recommendation system by offering a $50,000 prize for a 1% improvement. The Netflix Prize was started in 2006 but abandoned in 2010 in response to a lawsuit and Federal Trade Commission privacy concerns. Although the dataset released by Netflix to allow competition entrants to test their algorithms had supposedly been anonymised (i.e. by replacing user names with a meaningless ID and not including any gender or zip code information) a PhD student from the University of Texas was able to find out the real names of people in the supplied dataset by cross-referencing the Netflix dataset with Internet Movie Database (IMDB) ratings which people post publicly using their real names.
Herein lies the problem with the anonymisation of datasets. As Michael Kearns and Aaron Roth highlight in their recent book The Ethical Algorithm, when an organisation releases anonymised data they can try and make an intelligent guess as to which bits of the dataset to anonymise but it can be difficult (probably impossible) to anticipate what other data sources either already exist or could be made available in the future which could be used to correlate records. This is the reason that the computer scientist Cynthia Dwork has said “anonymised data isn’t” – meaning either it isn’t really anonymous or so much of the dataset has had to be removed that it is no longer data (at least in any useful way).
So what to do? Is it actually possible to release anonymised datasets out into the wild with any degree of confidence that they can never be de-anonymised? Thankfully something called differential privacy, invented by the aforementioned Cynthia Dwork and colleagues, allows us to do just that. Differential privacy is a system for publicly sharing information about a dataset by describing the patterns of groups within the dataset while withholding information about individuals in that dataset.
To understand how differential privacy works consider this example*. Suppose we want to conduct a poll of all people in London to find out who have driven after taking non-prescription drugs. One way of doing this is to randomly sample a suitable number of Londoners, asking them if they have ever driven whilst under the influence of drugs. The data collected could be entered into a spreadsheet and various statistics, e.g. number of men, number of women, maybe ages etc derived. The problem is that whilst collecting this information lots of compromising personal details may be collected which, if the data were stolen, could be used against them.
In order to avoid this problem consider the following alternative. Instead of asking people the question directly, first ask them to flip a coin but not to tell us how it landed. If the coin comes up heads they tell us (honestly) if they have driven under the influence. If it comes up tails however they tell us a random answer then flip the coin again and tell us “yes” if it comes up heads or “no” if it is tails. This polling protocol is a simple randomised algorithm which is a form of differential privacy. So how does this work?
If your answer is no, the randomised response answers no two out of three times. It answers no only one out of three times if your answer is yes. Diagram courtesy Michael Kearns and Aaron Roth, The Ethical Algorithm 2020
When we ask people if they have driven under the influence using this protocol half the time (i.e. when the coin lands heads up) the protocol tells them to tell the truth. If the protocol tells them to respond with a random answer (i.e. when the coin lands tails up), then half of that time they just happen to randomly tell us the right answer. So they tell us the right answer 1/2 + ((1/2) x (1/2)) or three-quarters of the time. The remaining one quarter of the time they tell us a lie. There is no way of telling true answers from lies. Surely though, this injection of randomisation completely masks the true results and the data is now highly error prone? Actually, it turns out, this is not the case.
Because we know how this randomisation is introduced we can reverse engineer the answers we get to remove the errors and get an approximation of the right answer. Here’s how. Suppose one-third of people in London have actually driven under the influence of drugs. So of the one-third who have truthfully answered “yes” to the question, three-quarters of those will answer “yes” using the protocol, that is 1/3 x 3/4 = 1/4. Of the two-thirds who have a truthful answer of “no”, one-quarter of those will report “yes”, that is 2/3 x 1/4 = 1/6. So we expect 1/4 + 1/6 = 5/12 ~ 1/3 of the population to answer “yes”.
So what is the point of doing the survey like this? Simply put it allows the true answer to be hidden behind the protocol. If the data were leaked and an individual from it was identified as being suspected of driving under the influence then they could always argue they were told to say “yes” because of the way the coins fell.
In the real world a number of companies including the US census, Apple, Google and Privitar Lens use differential privacy to limit the disclosure of private information about individuals whose information is in public databases.
It would be nice to think that the NHS data that is supposedly being used by US drug companies was protected by some form of differential privacy. If it were, and if this could be explained to the public in a reasonable and rational way, then surely we would all benefit both in the knowledge that our data is safe and is maybe even being put to good use in protecting and improving our health. After all, wasn’t this meant to be the true benefit of living in a connected society where information is shared for the betterment of all our lives?
*Based on an example from Kearns and Roth in The Ethical Algorithm.
It’s hard to believe that this year is the 30th anniversary of Tim Berners-Lee’s great invention, the World-Wide Web, and that much of the technology that enabled his creation is still less than 60 years old. Here’s a brief history of the Internet and the Web, and how we got to where we are today, in ten significant events.
#1: 1963 – Ted Nelson begins developing a model for creating and using linked content he calls hypertext and hypermedia. Hypertext is born.
#2: 1969 – The first message is sent over the ARPANET from computer science Professor Leonard Kleinrock’s laboratory at University of California, Los Angeles to the second network node at Stanford Research Institute. The Internet is born.
#3: 1969 – Charles Goldfarb, leading a small team at IBM, developed the first markup language, called Generalized Markup Language, or GML. Markup languages are born.
#4: 1989 – Tim Berners-Lee whilst working at CERN publishes his paper, Information Management: A Proposal. The World Wide Web (WWW) is born.
#5: 1993 – Mosaic, a graphical browser aiming to bring multimedia content to non-technical users (images and text on the same page) is invented by Marc Andreessen. The web browser is born.
#6: 1995 – Jeff Bezos launches Amazon “earth’s biggest bookstore” from a garage in Seattle. E-commerce is born.
#7: 1998 – The Google company is officially launched by Larry Page and Sergey Brin to market Google Search. Web search is born.
#8: 2003 – Facebook (then called FaceMash but changed to The Facebook a year later) is founded by Mark Zuckerberg with his college roommate and fellow Harvard University student Eduardo Saverin. Social media is born.
#9: 2007 – Steve Jobs launches the iPhone at MacWorld Expo in San Francisco. Mobile computing is born.
#10: 2018 – Tim Berners-Lee instigates act II of the web when he announces a new initiative called Solid, to reclaim the Web from corporations and return it to its democratic roots. The web is reborn?
I know there have been countless events that have enabled the development of our modern Information Age and you will no doubt think others should be included in preference to some of my suggestions. Also, I suspect that many people will not have heard of my last choice (unless you are a fairly hardcore computer type). The reason I have added this one is because I think/hope it will start to address what is becoming one of the existential threats of our age, namely how we survive in a world awash with data (our data) that is being mined and used without us knowing, much less understanding, the impact of such usage. Rather than living in an open society in which ideas and data are freely exchanged and used to everyones benefit we instead find ourselves in an age of surveillance capitalism which, according to this source, is defined as being:
…the manifestation of George Orwell’s prophesied Memory Hole combined with the constant surveillance, storage and analysis of our thoughts and actions, with such minute precision, and artificial intelligence algorithmic analysis, that our future thoughts and actions can be predicted, and manipulated, for the concentration of power and wealth of the very few.
In her book The Age of Surveillance Capitalism, Shoshana Zuboff provides a sweeping (and worrying) overview and history of the techniques that the large tech companies are using to spy on us in ways that even George Orwell would have found alarming. Not least because we have voluntarily given up all of this data about ourselves in exchange for what are sometimes the flimsiest of benefits. As Zuboff says:
Thanks to surveillance capitalism the resources for effective life that we seek in the digital realm now come encumbered with a new breed of menace. Under this new regime, the precise moment at which our needs are met is also the precise moment at which our lives are plundered for behavioural data, and all for the sake others gain.
Tim Berners-Lee invented the World-Wide Web then gave it away so that all might benefit. Sadly some have benefited more than others, not just financially but also by knowing more about us than most of us would ever want or wish. I hope for all our sakes the work that Berners-Lee and his small group of supporters is doing make enough progress to reverse the worst excesses of surveillance capitalism before it is too late.
This is the transcript of a talk I gave at the 2018 Colloquium on Responsibility in Arts, Heritage, Non-profit and Social Marketing at the University of Birmingham Business School on 17th September 2018.
Good morning everyone. My name is Peter Cripps and I work as a Software Architect for IBM in its Blockchain Division.
As a Software Architect my role is to help IBM’s clients understand blockchain and to architect systems built on this exciting new technology.
My normal world is that of finance, commerce and government computer systems that we all interact with on a day to day basis. In this talk however I’d like to discuss something a little bit different from my day to day role. I would like to explore with you how blockchain could be used to build a trust based system for the arts world that I believe could lead to a more responsible way for both creators and consumers of art to interact and transact to the mutual benefit of all parties.
First however let’s return to the role of the Software Architect and explain how two significant architectures have got us to where we are today (showing that the humble Software Architect really can change the world).
Architects take existing components and…
Seth on Architects
This is one of my favourite definitions of what architects do. Although Seth was talking about architects in the construction industry, it’s a definition that very aptly applies to Software Architects as well. By way of illustration here are two famous examples of how architects took some existing components and assembled them in very interesting ways.
1989: Tim Berners-Lee invents the World Wide Web
Tim Berners Lee and the World Wide Web
The genius of Tim Berners-Lee, when he invented the World Wide Web in 1989, was that he brought together three arcane technologies (hypertext, mark-up languages and Internet communication protocols) in a way no one had thought of before and literally transformed the world by democratising information. Recently however, as Berners Lee discusses in an interview in Vanity Fair, the web has begun to reveal its dark underside with issues of trust, privacy and so called fake news dominating much of the headlines over the past two years.
Interestingly, another invention some 20 years later, promises to address some of the problems now being faced by a society that is increasingly dependent on the technology of the web.
2008: Satoshi Nakamoto invents Bitcoin
Satoshi Nakamoto and Bitcoin
Satoshi Nakamoto’s paper Bitcoin: A Peer-to-Peer Electronic Cash System, that introduced the world to Bitcoin in 2009, also used three existing ideas (distributed databases, cryptography and proof-of-work) to show how a peer-to-peer version of electronic cash would allow online payments to be sent directly from one party to another without going through a financial institution. His genius idea, in a generalised form, was a platform that creates a new basis of trust for business transactions that could ultimately lead to a simplification and acceleration of the economy. We call this blockchain. Could blockchain, the technology that underpins Bitcoin, be the next great enabling technology that not only changes the world (again) but also puts back some of the trust in a the World Wide Web?
Blockchain: Snake oil or a miracle cure?
Miracle Cure or Snake Oil?
Depending on your point of view, and personal agenda, blockchain either promises to be a game changing technology that will help address such issues such as the world’s refugee crisis and the management of health supply chains or is the most over-hyped, terrifying and foolish technology ever. Like any new technology we need to be very careful to separate the hype from the reality.
What is blockchain?
Setting aside the hype, blockchain, at its core, is all about trust. It provides a mechanism that allows parties over the internet, who not only don’t trust each other but may not even know each other, to exchange ‘assets’ in a secure and traceable way. These assets can be anything from physical items like cars and diamonds or intangible ones such as music or financial instruments.
Here’s a definition of what a blockchain is.
An append-only, distributed system of record (a ledger) shared across a business network that provides transaction visibility to all involved participants.
Let’s break this down:
A blockchain is ‘append only’. That means once you’ve added a record (a block) to it you cannot remove it.
A blockchain is ‘distributed’ which means the ledger, or record book, is not just sitting in one computer or data centre but is typically spread around several.
A ‘system of record’ means that, at its heart, a blockchain is a record book describing the state of some asset. For example that a car with a given VIN is owned by me.
A blockchain is ‘shared’ which means all participants get their own copy, kept up to date and synchronised with all other copies.
Because it’s shared all participants have ‘visibility’ of the records or transactions of everyone else (if you want them to).
A business blockchain network has four characteristics…
Business blockchains can be characterised as having these properties:
Consensus
All parties in the network have to agree that a transaction is valid and that it can be added as a new block on the ledger. Gaining such agreement is referred to as consensus and various ways of reaching such consensus are available. One such consensus technique, which is used by the Bitcoin blockchain is referred to as proof-of-work. In Bitcoin proof-of-work is referred to as mining which is a highly compute intensive process as miners must compete to solve a mathematically complex problem to earn new coins. Because of its complexity, mining uses large amounts of computing power. In 2015 it was estimated that the Bitcoin mining network consumed about the same amount of energy as the whole of Ireland!
Happily, however, not all blockchain networks suffer from this problem as they do all not use proof-of-work as a consensus mechanism. Hyperledger, an open source software project owned and operated by the Linux Foundation , provides several different technologies that do not require proof-of-work as a consensus mechanism and so have vastly reduced energy requirements. Hyperledger was formed by over 20 founding companies in December 2015. Hyperledger blockchains are finding favour in the worlds of commerce, government and even the arts! Further, because Hyperledger is an open source project, anyone with access to the right skillset can build and operate their own blockchain network.
Immutability
This means that once you add a new block onto the ledger, it cannot be removed. It’s there for ever and a day. If you do need to change something then you must add a new record saying what that change is. The state of an asset on a blockchain is then the sum of all blocks that refer to asset.
Provenance
Because you can never remove a block from the ledger you can always trace back in time the history of assets being described on the ledger and therefore determine, for example, where it originated or how ownership has changed over time.
Finality
The shared ledger is the place that all participants agree stores ‘the truth’. Because the ledgers records cannot be removed and everyone has agreed them being recorded on there, that is the final source of truth.
… with smart contracts controlling who does what
Another facet of blockchain is the so called ‘smart contract’. Smart contracts are pieces of code that autonomously run on the blockchain, in response to some event, without the interference of a human being. Smart contracts change the state of the blockchain and are responsible for adding new blocks to the chain. In a smart contract the computer code is law and, provided all parties have agreed in advance the validity of that code, once it has run changes to the blockchain cannot be undone but become immutable. The blockchain therefore acts as a source of permanent knowledge about the state of an asset and allows the provenance of any asset to be understood. This is a fundamental difference between a blockchain and an ordinary database. Once a record is entered it cannot be removed.
Some blockchain examples
Finally, for this quick tour of blockchain, let’s take a look at a couple of industry examples that IBM has been working on with its clients.
The first is a new company called Everledger which aims to record on a blockchain the provenance of high value assets, such as diamonds. This allows people to know where assets have come from and how ownership has changed over time avoiding fraud and issues around so called ‘blood diamonds’ which can be used to finance terrorism and other illegal activities.
The second example is the IBM Food Trust Network, a consortium made up of food manufacturers, processors, distributors, retailers and others that allow for food to be tracked from ‘farm to fork’. This allows, for example, the origin of a particular food to be quickly determined in the case of a contamination or outbreak of disease and for only effected items to be taken out the supply chain.
What issues can blockchain address in the arts world?
In the book Artists Re:Thinking the Blockchain various of the contributors discuss how blockchain could be used to create new funding models for the arts by the “renegotiation of the economic and social value of art” as well as helping artists “to engage with new kinds of audiences, patrons and participants.” (For another view of blockchain and the arts see the documentary The Blockchain and Us).
I also believe blockchain could help tackle some of the current problems around trust and lack of privacy on the web as well as address issues around the accumulation of large amounts of user generated content at virtually no cost to the owners in what the American computer scientist Jaron Lanier calls “siren-servers” .
Let’s consider two aspects of the art world that blockchain could address:
Trust
As a creator how do I know people are using my art work legitimately? As a consumer how do I know the creator of the art work is who they say they are and the art work is authentic?
Value
As a creator how do I get the best price for my art work? As a consumer how do I know I am not paying too much for an art work?
Challenges/issues of the global art market (and how blockchain could address them)
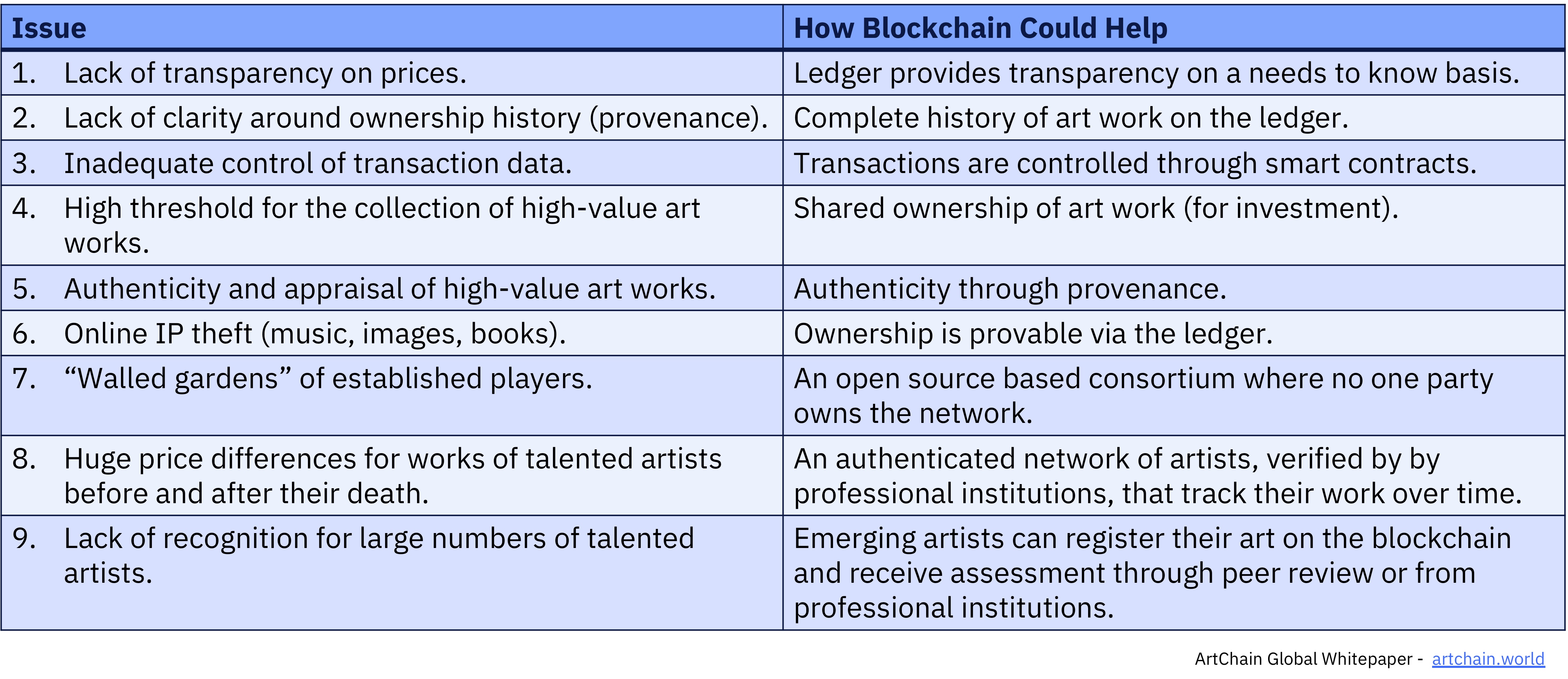
Let’s drill down a bit more into what some of these issues are and how a blockchain network could begin to address them. Here’s a list of nine key issues that various players in the world of arts say impacts the multi-billion pound art market and which blockchain could help address in the ways I suggest.
To be clear, not all of these issues will be addressed by technology alone. As with any system that is introduced it needs not only the buy-in of the existing players but also a sometimes radical change in the underlying business model that the current system has developed. ArtChain is one such company that is looking to use blockchain to address some of these issues. Another is the online photography community YouPic.
Introducing YouPic Blockchain
YouPic is an online community for photographers which allows photographers to not only share their images but also receive payment. YouPic is in the process of implementing a blockchain that allows photographers to retain more control over their images. For example:
Copyright attribution.
Image tracking and copyright tools.
Smart contracts for licensing
Every image has a unique fingerprint so when you look up the fingerprint or a version of the image it points out all of the licensing information the creator has listed.
The platform could, for example, search the web to identify illicit uses of images and if identified contact the creator to notify them of a potential copyright breach.
You could also use smart contracts to manage you images automatically, e.g. receive payments in different currencies, or maybe you want to distribute payment to other contributors or just file a claim if your image is used without your consent.
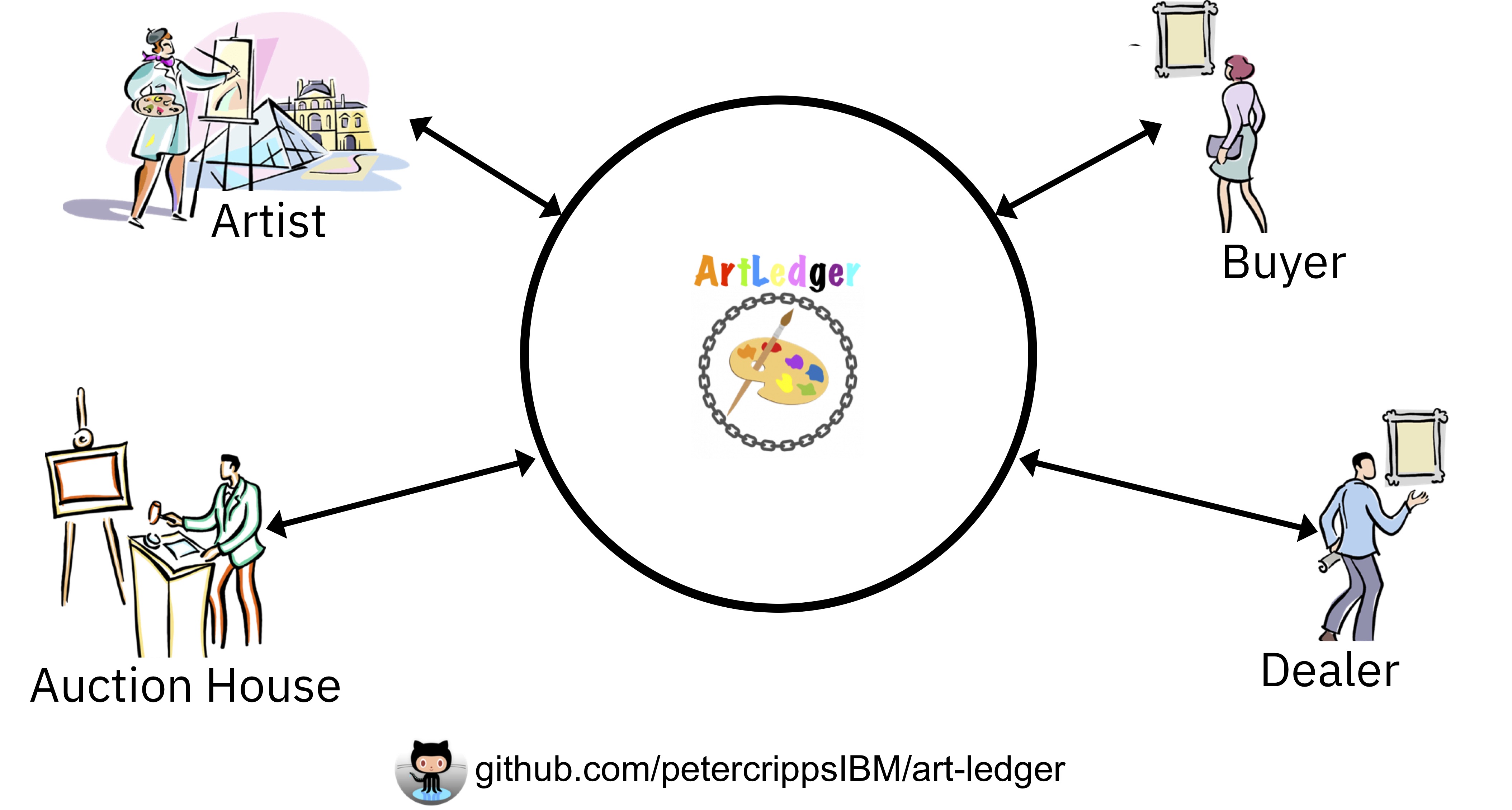
ArtLedger
ArtLedger is a sandbox I am developing for exploring some of these ideas. It’s open source and available on GitHub. I have a very rudimentary proof of concept running in the IBM Cloud that allows you to interact with a blockchain network with some of these actors.
I’m encouraging people to go onto my GitHub project, take a look at the code and the instructions for getting it working and have a play with the live system. I will be adapting it over time to add more functions and see how the issues in the previous stage could be addressed as well as exploring funding models for how such a network could become established and grow.
Summary
So, to summarise:
Blockchains can provide a system that engenders trust through the combined attributes of: Consensus; Immutability; Provenance; Finality.
Consortiums of engaged participants should build networks where all benefit.
Many such networks are at the early stages of development. It is still early days for the technology but results are promising and, for the right use cases, systems based on blockchain have the promise of another step change in driving the economy in a fairer and more just way.
For the arts world blockchain holds the promise of engaging with new kinds of audiences, patrons and participants and maybe even the creation of new funding models.
The genius of Tim Berners-Lee when he invented the World Wide Web back in 1989 was that he brought together three arcane technologies (hypertext, markup languages and internet communication protocols) in a way no one had thought of before and literally transformed the world. Could blockchain do the same thing? Satoshi Nakamoto in his paper that introduced the world to bitcoins 20 years later in 2009 also used three existing ideas (distributed databases, public key or asymetric cryptography and proof-of-work) to show how a peer-to-peer version of electronic cash would allow online payments to be sent directly from one party to another without going through a financial institution.
Depending on your point of view, and personal agenda, blockchain the technology that underpins Bitcoin, either promises to do no less than solve the world’s refugee crisis and transform the management of health supply chains or is the most over-hyped, terrifying and foolish technology since Google Glass or MySpace. Like any new technology we need to be very careful to separate the hype from the reality.
The documentary The Blockchain and Us made by Manuel Stagars in 2017 interviews software developers, cryptologists, researchers, entrepreneurs, consultants, VCs, authors, politicians, and futurists from around the world and poses a number of questions such as: How can the blockchain benefit the economies of nations? How will it change society? What does it mean for each of us? The intent of the film is not to explain the technology but to give views on the it and encourage a conversation about its potential wider implications.
Since I have begun to focus my architecture efforts on blockchain I often get asked the question that is the title of this blog post. According to Gartner blockchain has gone through the ‘peak of inflated expectations’ and is now sliding down into the ‘trough of disillusionment’. The answer to the question, as is the case for most new technologies, will be it’s “good for” some things but not everything.
As a technologist it pains me to say this but in the business world technology itself is not usually the answer to anything on its own. As the Venture Capitalist Jimmy Song said at Consensus earlier this year*, “When you have a technology in search of a use, you end up with the crap that we see out there in the enterprise today.” Harsh words indeed but probably true.
Instead, what is needed is the business and organisational change that drives new business models in which technology is, if required, slotted in at the right time and place. Business people talk about the return on investment of tech and the fact that technology often “gobbles up staff time and money, without giving enough back“. Blockchain runs the risk of gobbling up too much time and money if the right considerations are not given to its use and applicability to business.
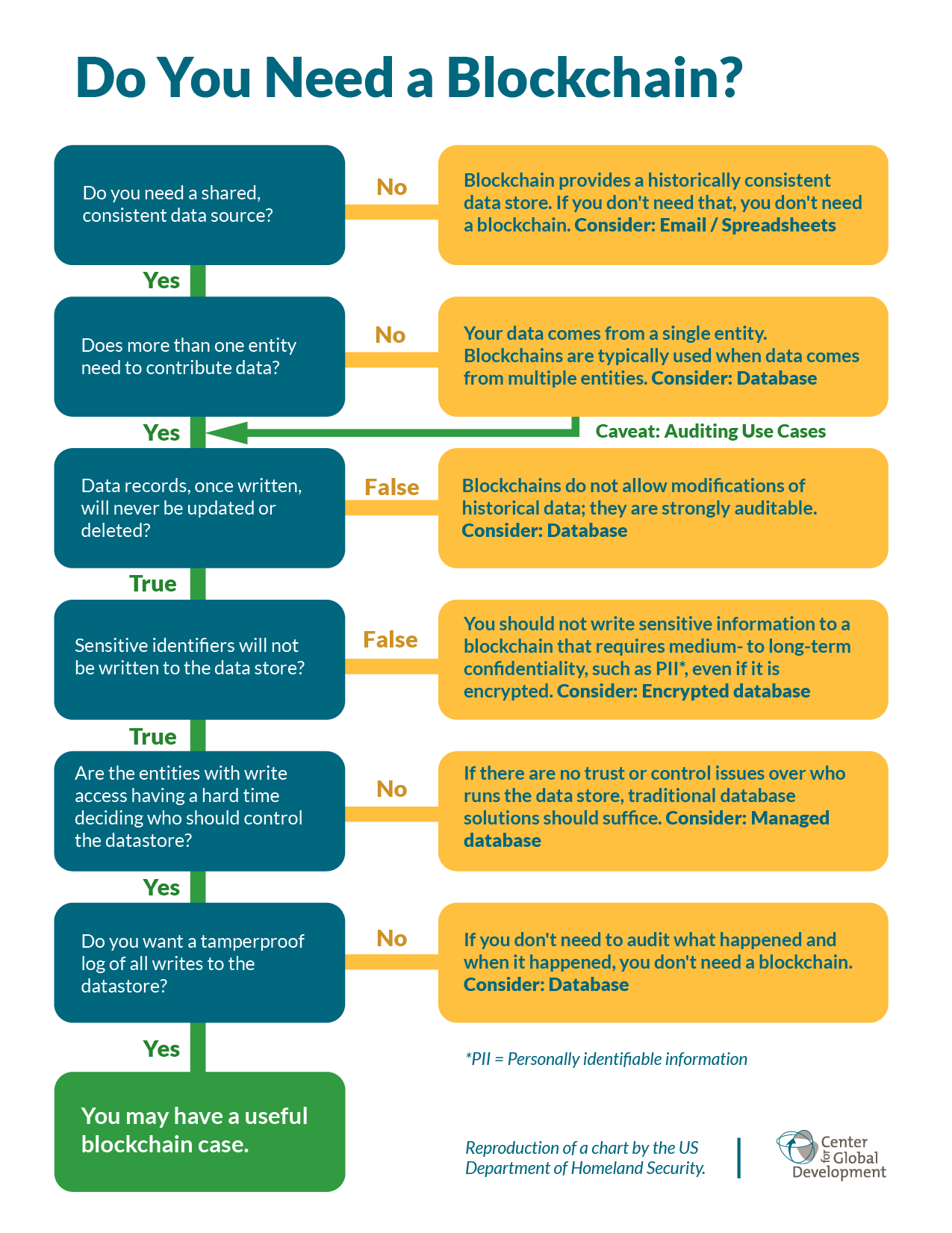
If we are to ensure blockchain has a valid business use and gets embedded into the technology stack that businesses use then we need to ensure the right questions get asked when considering its use. As a start in doing this you could do worse than consider this set of questions from the US Department for Homeland Security.
Many blockchain projects are still at the proof of technology stage although there are some notable exceptions. The IBM Food Trust is a collaborative network of growers, processors, wholesalers, distributors, manufacturers, retailers and others enhancing visibility and accountability in each step of the food supply chain whilst the recently announced TradeLens aims to apply blockchain to the world’s global supply chain. Both of these solutions are built on top of the open source Hyperledger Fabric blockchain platform which is one of the projects under the umbrella of the Linux Foundation.
What these and other successful blockchain systems are showing is actually that another question should be tagged onto the flowchart above (probably it should be the first question). This would be something like: “Are you willing to be part of a collaborative business network to share information on a needs to know basis?” The thing about permissioned networks like Hyperledger Fabric is that people don’t need to trust everyone on the network but they do need to agree who will be a part of it. Successful blockchain business networks are proving to be the ones whose participants understand this and are willing to collaborate.
Today (12th March, 2018) is the World Wide Web’s 29th birthday. Sir Tim Berners-Lee (the “inventor of the world-wide web”), in an interview with the Financial Times and in this Web Foundation post has used this anniversary to raise awareness of how the web behemoths Facebook, Google and Twitter are “promoting misinformation and ‘questionable’ political advertising while exploiting people’s personal data”. Whilst I admire hugely Tim Berners-Lee’s universe-denting invention it has to be said he himself is not entirely without fault in the wayhe bequeathed us with his invention. In his defence, hindsight is a wonderful thing of course, no one could have possibly predicted at the time just how the web would take off and transform our lives both for better and for worse.
If, as Marc Andreessen famously said in 2011, software is eating the world then many of those powerful tech companies are consuming us (or at least our data and I’m increasingly becoming unsure there is any difference between us and the data we choose to represent ourselves by.
Here are five recent examples of some of the negative ways software is eating up our world.
Over the past 40+ years the computer software industry has undergone some fairly major changes. Individually these were significant (to those of us in the industry at least) but if we look at these changes with the benefit of hindsight we can see how they have combined to bring us to where we are today. A world of cheap, ubiquitous computing that has unleashed seismic shocks of disruption which are overthrowing not just whole industries but our lives and the way our industrialised society functions. Here are some highlights for the 40 years between 1976 and 2016.
And yet all of this is just the beginning. This year we will be seeing technologies like serverless computing, blockchain, cognitive and quantum computing become more and more embedded in our lives in ways we are only just beginning to understand. Doubtless the fallout from some of the issues I highlight above will continue to make themselves felt and no doubt new technologies currently bubbling under the radar will start to make themselves known.
I have written before about how I believe that we, as software architects, have a responsibility, not only to explain the benefits (and there are many) of what we do but also to highlight the potential negative impacts of software’s voracious appetite to eat up our world.
This is my 201st post on Software Architecture Zen (2016/17 were barren years in terms of updates). This year I plan to spend more time examining some of the issues raised in this post and look at ways we can become more aware of them and hopefully not become so seduced by those sirenic entrepreneurs.
As software architects we often get wrapped up in ‘the moment’ and are so focused on the immediate project deliverables and achieving the next milestone or sale that we rarely step back to consider the bigger picture and wider ethical implications of what we are doing. I doubt many of us really think whether the application or system we are contributing to in some way is really one we should be involved in or indeed is one that should be built at all.
To be clear, I’m not just talking here about software systems for the defence industry such as guided missiles, fighter planes or warships which clearly have one very definite purpose. I’m assuming that people who do work on such systems have thought, at least at some point in their life, about the implications of what they are doing and have justified it to themselves. Most times this will be something along the lines of these systems being used for defence and if we don’t have them the bad guys will surely come and get us. After all, the doctrine of mutual assured destruction (MAD) fueled the cold war in this way for the best part of fifty years.
Instead, I’m talking about systems which whilst on the face of it are perfectly innocuous, over time grow into behemoths far bigger than was ever intended and evolve into something completely different from their original purpose.
Obviously the biggest system we are are all dealing with, and the one which has had a profound effect on all of our lives, whether we work to develop it or just use it, is the World Wide Web.
The Web is now in its third decade so is well clear of those tumultuous teenage years of trying to figure out its purpose in life and should now be entering a period of growing maturity and and understanding of where it fits in the world. It should be pretty much ‘grown up’ in fact. However the problem with growing up is that in your early years at least you are greatly influenced, for better or worse, by your parents.
“I articulated the vision, wrote the first Web programs, and came up with the now pervasive acronyms URL, HTTP, HTML, and , of course World Wide Web. But many other people, most of them unknown, contributed essential ingredients, in much the same, almost random fashion. A group of individuals holding a common dream and working together at a distance brought about a great change.”
One of the “unknown” people (at least outside of the field of information technology) was Ted Nelson. Ted coined the term hypertext in his 1965 paper Complex Information Processing: A File Structure for the Complex, the Changing, and the Indeterminate and founded Project Xanadu (in 1960) in which all the worlds information could be published in hypertext and all quotes, references etc would be linked to more information and the original source of that information. Most crucially, for Nelson, was the fact that because every quotation had a link back to its source the original author of that quotation could be compensated in some small way (i.e. using what we now term micro-payments). Berners-Lee borrowed Nelson’s vision for hypertext which is what allows all the links you see in this post to work, however with one important omission.
Nelson himself has stated that some aspects of Project Xanadu are being fulfilled by the Web, but sees it as a gross over-simplification of his original vision:
“HTML is precisely what we were trying to PREVENT— ever-breaking links, links going outward only, quotes you can’t follow to their origins, no version management, no rights management.”
The last of these omissions (i.e. no rights management) is possibly one of the greatest oversights in the otherwise beautiful idea of the Web. Why?
Jaron Lanier the computer scientist, composer and author explains the difference between the Web and what Nelson proposed in Project Xanadu in his book Who Owns the Future as follows:
“A core technical difference between a Nelsonian network and what we have become familiar with online is that [Nelson’s] network links were two-way instead of one-way. In a network with two-way links, each node knows what other nodes are linked to it. … Two-way linking would preserve context. It’s a small simple change in how online information should be stored that couldn’t have vaster implications for culture and the economy.”
So what are the cultural and economic implications that Lanier describes?
In both Who Owns the Future and his earlier book You Are Not a Gadget Lanier articulates a number of concerns about how technology, and more specifically certain technologists, are leading us down a road to a dystopian future where not only will most middle class jobs be almost completely wiped out but we will all be subservient to a small number of what Lanier terms siren servers. Lanier defines a siren server as “an elite computer or coordinated collection of computers, on a network characterised by narcissism, hyper amplified risk aversion, and extreme information asymmetry”. He goes on to make the following observation about them:
“Siren servers gather data from the network, often without having to pay for it. The data is analysed using the most powerful available computers, run by the very best available technical people. The results of the analysis are kept secret, but are used to manipulate the rest of the world to advantage.”
Lanier’s two books tend to ramble a bit but nonetheless contain a number of important ideas.
Idea #1: Is the one stated above that because we essentially rushed into building the Web without thinking of the implications of what we were doing we have built up a huge amount of technical debt which could well be impossible to eradicate.
Idea #2: The really big siren servers (i.e. Facebook, Google, Twitter et al) have encouraged us to upload the most intimate details of our lives and in return given us an apparently ‘free’ service. This however has encouraged us to not want to pay for any services, or pay very little for them. This makes it difficult for any of the workers who create the now digitised information (e.g. journalists, photographers and musicians) to earn a decent living. This is ultimately an economically unsustainable situation however because once those information creators are put out of business who will create original content? The world cannot run on Facebook posts and tweets alone. As the musician David Byrne says here:
“The Internet has laid out a cornucopia of riches before us. I can read newspapers from all over the world, for example—and often for free!—but I have to wonder if that feast will be short-lived if no one is paying for the production of the content we are gorging on.”
Idea #3: The world is becoming overly machine centric and people are too ready to hand over a large part of their lives to the new tech elite. These new sirenic entrepreneurs as Lanier calls them not only know far too much about us but can use the data we provide to modify our behaviour. This may either be deliberately in the case of an infamous experiment carried out by Facebook or in unintended ways we as a society are only just beginning to understand.
Idea #4: Is that the siren servers are imposing a commercial asymmetry on all of us. When we used to buy our information packaged in a physical form it was ours to do with as we wished. If we wanted to share a book, or give away a CD or even sell a valuable record for a profit we were perfectly at liberty to do so. Now all information is digital however we can no longer do that. As Lanier says “with an ebook you are no longer a first-class commercial citizen but instead have tenuous rights within someone else’s company store.” If you want to use a different reading device or connect over a different cloud in most cases you will lose access to your purchase.
There can be little doubt that the Web has had a huge transformative impact on all of our lives in the 21st century. We now have access to more information than it’s possible to assimilate the tiniest fraction of in a human lifetime. We can reach out to almost any citizen in almost any part of the world at any time of the day or night. We can perform commercial transactions faster than ever would have been thought possible even 25 years ago and we have access to new tools and processes that genuinely are transforming our lives for the better. This however all comes at a cost even when access to all these bounties is apparently free. As architects and developers who help shape this brave new world should we not take responsibility to not only point out where we may be going wrong but also suggest ways in which we should improve things? This is something I intend to look at in some future posts.
Almost three years ago to the day on here I wrote a post called Happy 2013 and Welcome to the Fifth Age! The ‘ages’ of (commercial) computing discussed there were:
First Age: The Mainframe Age (1960 – 1975)
Second Age: The Mini Computer Age (1975 – 1990)
Third Age: The Client-Server Age (1990 – 2000)
Fourth Age: The Internet Age (2000 – 2010)
Fifth Age: The Mobile Age (2010 – 20??)
One of the things I wrote in that article was this:
“Until a true multi-platform technology such as HTML5 is mature enough, we are in a complex world with lots of new and rapidly changing technologies to get to grips with as well as needing to understand how the new stuff integrates with all the old legacy stuff (again). In other words, a world which we as architects know and love and thrive in.”
So, three years later, are we any closer to having a multi-platform technology? Where does cloud computing fit into all of this and is multi-platform technology making the world get more or less complex for us as architects?
In this post I argue that cloud computing is actually taking us to an age where rather than having to spend our time dealing with the complexities of the different layers of architecture we can be better utilised by focussing on delivering business value in the form of new and innovative services. In other words, rather than us having to specialise as layer architects we can become full-stack architects who create value rather than unwanted or misplaced technology. Let’s explore this further.
The idea of the full stack architect.
Vitruvius, the Roman architect and civil engineer, defined the role of the architect thus:
“The ideal architect should be a [person] of letters, a mathematician, familiar with historical studies, a diligent student of philosophy, acquainted with music, not ignorant of medicine, learned in the responses of juriconsults, familiar with astronomy and astronomical calculations.”
Vitruvius also believed that an architect should focus on three central themes when preparing a design for a building: firmitas (strength), utilitas (functionality), and venustas (beauty).
Vitruvian Man by Leonardo da Vinci
For Vitruvius then the architect was a multi-disciplined person knowledgable of both the arts and sciences. Architecture was not just about functionality and strength but beauty as well. If such a person actually existed then they had a fairly complete picture of the whole ‘stack’ of things that needed to be considered when architecting a new structure.
So how does all this relate to IT?
In the first age of computing (roughly 1960 – 1975) life was relatively simple. There was a mainframe computer hidden away in the basement of a company managed by a dedicated team of operators who guarded their prized possession with great care and controlled who had access to it and when. You were limited by what you could do with these systems not only by cost and availability but also by the fact that their architectures were fixed and the choice of programming languages (Cobol, PL/I and assembler come to mind) to make them do things was also pretty limited. The architect (should such a role have actually existed then) had a fairly simple task as their options were relatively limited and the number of architectural decisions that needed to be made were correspondingly fairly straight forward. Like Vitruvias’ architect one could see that it would be fairly straight forward to understand the full compute stack upon which business applications needed to run.
Indeed, as the understanding of these computing engines increased you could imagine that the knowledge of the architects and programmers who built systems around these workhorses of the first age reached something of a ‘plateau of productivity’*.
However things were about to get a whole lot more complicated.
The fall of the full stack architect.
As IT moved into its second age and beyond (i.e. with the advent of mini computers, personal computers, client-server, the web and early days of the internet) the breadth and complexity of the systems that were built increased. This is not just because of the growth in the number of programming languages, compute platforms and technology providers but also because each age has built another layer on the previous one. The computers from a previous age never go away, they just become the legacy that subsequent ages must deal with. Complexity has also increased because of the pervasiveness of computers. In the fifth age the number of people whose lives are now affected by these machines is orders of magnitude greater than it was in the first age.
All of this has led to niches and specialisms that were inconceivable in the early age of computing. As a result, architecting systems also became more complex giving rise to what have been termed ‘layer’ architects whose specialities were application architecture, infrastructure architecture, middleware architecture and so on.
Whole professions have been built around these disciplines leading to more and more specialisation. Inevitably this has led to a number of things:
The need for communications between the disciplines (and for them to understand each others ‘language’).
As more knowledge accrues in one discipline, and people specialise in it more, it becomes harder for inter-disciplinary understanding to happen.
Architects became hyper-specialised in their own discipline (layer) leading to a kind of ‘peak of inflated expectations’* (at least amongst practitioners of each discipline) as to what they could achieve using the technology they were so well versed in but something of a ‘trough of disillusionment’* to the business (who paid for those systems) when they did not deliver the expected capabilities and came in over cost and behind schedule.
So what of the mobile and cloud age which we now find ourselves in?
The rise of the full stack architect.
As the stack we need to deal with has become more ‘cloudified’ and we have moved from Infrastructure as a Service (IaaS) to Platform as a Service (PaaS) it has become easier to understand the full stack as an architect. We can, to some extent, take for granted the lower, specialised parts of the stack and focus on the applications and data that are the differentiators for a business.
We no longer have to worry about what type of server to use or even what operating system or programming environments have to be selected. Instead we can focus on what the business needs and how that need can be satisfied by technology. With the right tools and the right cloud platforms we can hopefully climb the ‘slope of enlightenment’ and reach a new ‘plateau of productivity’*.
As Neal Ford, Software Architect at Thoughtworks says in this video:
“Architecture has become much more interesting now because it’s become more encompassing … it’s trying to solve real problems rather than play with abstractions.”
I believe that the fifth age of computing really has the potential to take us to a new plateau of productivity and hopefully allow all of us to be architects described by this great definition from the author, marketeer and blogger Seth Godin:
“Architects take existing components and assemble them in interesting and important ways.”
What interesting and important things are you going to do in this age of computing?