Last week I attended the Smart City and Government Open Data Hackathon in Birmingham, UK. The event was sponsored by IBM and my colleague Dr Rick Robinson, who writes extensively on Smarter Cities as The Urban Technologist, gave the keynote session to kick off the event. The idea of this particular hackathon was to explore ways in which various sources of open data, including the UK governments own open data initiative, could be used in new and creative ways to improve the lives of citizens and make our cities smarter as well as generally better places to live in. There were some great ideas discussed including how to predict future jobs as well as identifying citizens who had not claimed benefits to which they were entitled (and those benefits then going back into the local economy through purchases of goods and services).The phrase “data is the new oil” is by no means a new one. It was first used by Michael Palmer in 2006 in this article. Palmers says:
Data is just like crude. It’s valuable, but if unrefined it cannot really be used. It has to be changed into gas, plastic, chemicals, etc to create a valuable entity that drives profitable activity; so must data be broken down, analyzed for it to have value.
Whilst this is a nice metaphor I think I actually prefer the slight adaptation proposed by David McCandless in his TED talk: The beauty of data visualization where he coins the phrase “data is the new soil”. The reason being data needs to be worked and manipulated, just like a good farmer looking after his land, to get the best out of it. In the case of the work done by McCandless this involves creatively visualizing data to show new understandings or interpretations and, as Hans Rosling says, to let the data set change your mind set.
Certainly one way data is most definitely not like oil is in the way it is increasing at exponential rates of growth rather than rapidly diminishing. But it’s not only data. The new triumvirate of data, cloud and mobile is forging a whole new mega-trend in IT nicely captured in this equation proposed by Gabrielle Byrne at the start of this video:
Where:
- e is any enterprise (or city, see later)
- m is mobile
- c is cloud
- imc is in memory computing, or stream computing, the instant analysis of masses of fast changing data
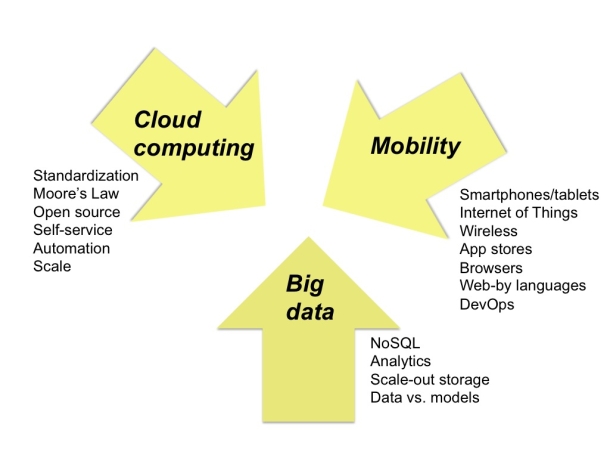
This new trend is characterized by a number of incremental innovations that have taken place in IT over previous years in each of the three areas nicely captured in the figure below.
 |
| Source: CNET – Where IT is going: Cloud, mobile and data |
In his blog post: The new architecture of smarter cities, Rick proposes that a Smarter City needs three essential ‘ingredients’ in order to be really characterized as ‘smart’. These are:
- Smart cities are led from the top
- Smart cities have a stakeholder forum
- Smart cities invest in technology infrastructure
It is this last attribute that, when built on a suitable cloud-mobility-data platform, promises to fundamentally change not only how enterprises are set to change but also cities and even whole nations. However it’s not just any old platform that needs to be built. In this post I discussed the concept behind so-called disruptive technology platforms and the attributes they must have. Namely:
- A well defined set of open interfaces.
- A critical mass of both end users and service providers.
- Both scaleable and extremely robust.
- An intrinsic value which cannot be obtained elsewhere.
- Allow users to interact amongst themselves, maybe in ways that were originally envisaged.
- Service providers must be given the right level of contract that allows them to innovate, but without actually breaking the platform.
So what might a disruptive technology platform, for a whole city, look like and what innovations might it provide? As an example of such a platform IBM have developed something they call the Intelligent Operations Center or IOC. The idea behind the IOC is to use information from a number of city agencies and departments to make smarter decisions based on rules that can be programmed into the platform. The idea then, is that the IOC will be used to anticipate problems to minimize the impact of disruptions to city services and operations as well as assist in the mobilization of resources across multiple agencies. The IOC allows aggregated data to be visualized in ways that the individual data sets cannot and for new insights to be obtained from that data.
Platforms like the IOC are only the start of what is possible in a truly smart city. They are just beginning to make use of mobile technology, data in the cloud and huge volumes of fast moving data that is analysed in real-time. Whether these platforms turn out to be really disruptive remains to be seen but if this is really the age of “new oil” then we only have the limitations of our imagination to restrict us in how we will use that data to give us valuable new insights into building smart cities.